背景知识
cpu 流水线
一段指令的执行大致可分为取指–译指–执行–写回4个阶段,在单流水线的情况下运行如下:
| 取指单元 | 译指单元 | 执行单元 | 写回单元 | |
|---|---|---|---|---|
| 时钟周期1 | 取指1 | |||
| 时钟周期2 | 译指1 | |||
| 时钟周期3 | 执行1 | |||
| 时钟周期4 | 写回1 |
在每个时钟周期内,只有一个执行单元在运行,其他三个执行单元都处于闲置等待状态,因此一条指令执行完成需要4个时钟周期。
为了提高CPU的吞吐率,当前CPU架构一般都采用了多流水线技术,可以在同一个时钟周期内并行执行多条指令:
| 取指单元 | 译指单元 | 执行单元 | 写回单元 | |
|---|---|---|---|---|
| 时钟周期1 | 取指1 | |||
| 时钟周期2 | 取指2 | 译指1 | ||
| 时钟周期3 | 取指3 | 译指2 | 执行1 | |
| 时钟周期4 | 取指4 | 译指3 | 执行2 | 写回1 |
| 时钟周期5 | 取指5 | 译指4 | 执行3 | 写回2 |
| 时钟周期6 | 取指6 | 译指5 | 执行4 | 写回3 |
只有在第一个时钟周期内,其他单元闲置,在第2个时钟周期时,第一条流水线译指1时,第2条流水线开始取第2条指令,如此循环,多级流水线就并行起来,假设每个单元执行的耗时是2ns,那CPU的主频就是500MHz。
但是由于不同阶段的耗时可能不太一样,因此流水线上执行时间最长的单元决定了整条流水线流转的性能,比如其他单元2ns,执行单元4ns,那CPU的主频就降为了250MHz。因此,为了提升CPU主频,需要减少流水线中每一级的执行时间,并找到耗时最长的瓶颈,进行细分拆解,消除木桶短板,使流水线中每个单元的执行耗时尽可能的相等,来提高整体流水线的吞吐率。
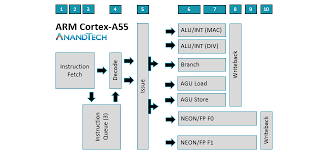
5级以上的流水线称为超流水线结构,如,Inter i7有16级,Cortex A53和A55的流水线是双发射8级流水线:
流水线越深,性能就一定越高吗?
不一定,流水线靠指令并行提升性能,在执行第一条指令时,进行第二条指令的取指和译码,如果编译的程序指令都是顺序的,没有中断或跳转,这种情况可以线性的提高执行效率。但是当程序指令中存在跳转和分支判断时,CPU预取的指令和数据如果预测失败,可能就会全部丢掉重新取指,因此流水线越深,预取的指令和数据miss后重新加载的成本就越高;另外流水线越深,就需要更多的组合逻辑电路和寄存器,芯片面积和功耗会随之变大。
多发射是指在在一个时钟周期内可以执行多条指令,比如在一个时钟周期内,同时发送多条指令到不同的执行单元,从而达到指令级的并行。一个双发射处理器每个时钟周期理论上最多可执行2条指令,理想的ipc为2.0
流水线冒险
结构冒险
如果多条指令的执行都依赖同一硬件资源,如ALU,寄存器访问等,就会发生 “硬件资源” 冲突,导致只能串行执行,称之为结构冒险。
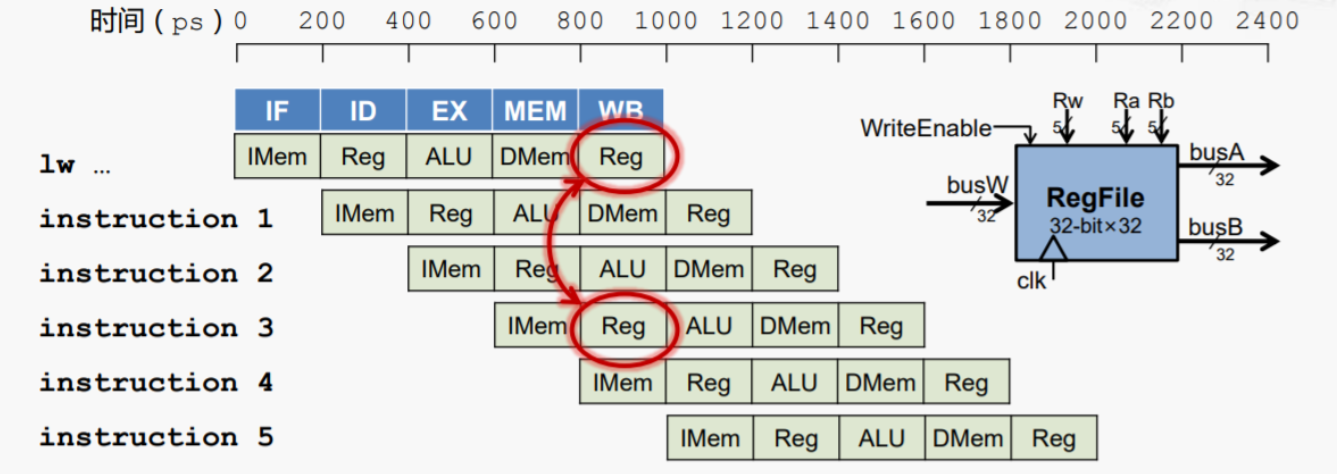 结构冒险的解决方法有插入空指令、编译器静态或者硬件电路动态的对寄存器进行重命名等
结构冒险的解决方法有插入空指令、编译器静态或者硬件电路动态的对寄存器进行重命名等
上图为寄存器读写冲突
数据冒险
数据冒险是指前后指令存在依赖关系,当前指令的执行需要上一条指令的运算结果,比如第2条SUB指令要等待第一条ADD指令将结果写回R2寄存器才能执行
解决方法是插入空指令,暂停SUB指令的执行,等待ADD指令结束,还有一种”operand fowarding”技术,在ADD指令执行阶段完毕后,不再执行WB写回寄存器操作,而是直接使用运算结果到SUB指令。插入空指令会让流水线暂时停顿(stall), 产生空泡(bubble),但是当流水线很深时,总比把后边已经预取的几十条指令全部丢掉要划算的多。
控制冒险
如果程序中存在大量的条件判断指令,CPU无法确定接下来会走到哪个分支取哪些指令。虽然可以通过插入更多的空泡来等待结果避免控制冒险,但当流水线很深时,大量的空泡也会带来严重的性能开销。
解决方法是条件预测:当CPU流水线在取指和译码时,会对跳转指令进行分析,预测可能执行的分支和路径,尽量减少预取错误的分支路径指令导致流水线的清空与停顿。
手动干预预测:在随机或者无序的情况下可能会带来一定的性能提升,但是在常规场景几乎很难带来正向收益,编译器做的已经是很好了。
#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x), 0)
if(likely(cond)){...}
缓存与缓存一致性
Cache是用来解决CPU执行速度较快,内存访问较慢引入的高速缓存,用来提高CPU访问的效率。
缓存一般分为3级,L1分为i-cache与d-cache,离CPU最近,访问速度最快,容量也最小,L2容量相对较大,L1与L2每个cpu核独占,L3容量最大,访问速度相对较慢,所有核共享。
CPU访问的数据会从内存-L3-L2-L1中顺序加载并访问,如果CPU要访问的数据没有在L1缓存中,则发生了cache-misses【对应perf事件为L1-dcache-load-misses】,此时会从L2中读取并加载到L1,如果L2也没有,会从L3读取加载到L2,如果L3也没有,会从内存中加载到L3-L2-L1,而每次访存都要消耗几个时钟周期,因此会降低CPU的执行效率。
缓存的最小单位为cache line,访问内存的耗时与访问的字节数量无关,和访问的每个字节所在的缓存行数量有关;缓存行决定数据的粒度,应该尽可能的让连续访问的数据紧凑排列到一个缓存行,最好里边要么没数据,要么有数据,避免读取缓存行浪费一部分空间没用
多核MESI协议与伪共享
缓存一致性协议:每个cacheline有Modified/Exclusive/Shared/Invalid四种状态,用来解决多核之间缓存不一致问题。
位于同一缓存行的两个变量a和b被2个cpu加载到各自的L1 cache中,修改前cache line都是shared的,然后cpu0 和 cpu1都想去修改cache line中对应memory中的同一变量,cpu0争到主导权后去更新cache line中的数据,会导致cpu1中的cache line状态变为Invalid,随后thread 1去更新时必须通知cpu 0将cache line刷回主存,然后再从memory中load进cache line去修改,而该修改又会导致cpu 0中的cache line Invalid,然后cpu 0访问时会通知cpu 1将cache line刷回主存再去加载,往复循环,造成高速缓存的效率低下从而影响性能;
解决方法有cache line padding:填充缓存行,在a和b变量中间插入一个长度为缓存行的数组,以空间换时间,避免两个线程同时往同一个变量或缓存行中写以避免伪共享。
可通过perf c2c来查看伪共享问题,伪共享问题可参考:https://www.cnblogs.com/diegodu/p/9340243.html
常用分析工具
perf
perf top
热点函数获取
//实时查看所有用户空间的top热点【绝对cpu占比】
perf top -aK
// 查看查看进程内的热点函数占比
perf top -a -p pid //-K 【只看用户空间占比】
// 以动态共享库为单位,统计每个dso的cpu占比 ,可以跟踪查看某个库的资源占用
perf top -K --sort dso
// 指定查看某个cpu核上的符号占比
perf top -C 1-8 -p pid
// 查看 cache-misses 的top函数
perf top -e cache-misses -p pid
// 查看 branch-misses 的top函数
perf top -e branch-misses -p pid -aK
// 查看某个进程的上下文切换的top函数
perf top -e context-switches -p pid
perf stat
统计并输出程序在某一段时间内执行的性能肖像数据,如执行的周期数cycles,指令数instructions,分支判断branchses及branch-miesses,缺页次数,上下文切换/cpu迁移次数,cache load与misses次数,如果某个指标占比过高,会用不同的颜色标示出来
//统计某个线程或某个进程30s并将结果输出到result.txt文件
perf stat -d -p pid -t tid -o result.txt --sleep 30
//直接启动测量某个进程的各种事件
perf stat -e branch-misses/cache-misses/LLC-load-misses ./demo
- CPUS utilized = task-clock / time elapsed 值越大说明cpu利用率越高
- IPC = instructions / cycles 执行的指令数(instructions) / 消耗的指令周期数
- branch-miss: 分支预测失败百分比,branch-misses/branches 一般来说,性能最理想的情况下,ipc接近于流水线数,可以作为一个宏观上的性能优化指标,也可以从一定程度上反应一个方法的可优化空间;
其次执行的指令数 instructions 与 branches 分支判断次数,可以直观的作为优化的一个指标,比如去掉了几个乘法,会对应减少instructions 数量,或者合并了几个if判断,会对应减少一定的branches执行指令数。
但是instructions 与 cyles并没有太直接的线性关系,性能更优吞吐量更高的代码会在一定时间内执行的指令数比相对较低的代码要多
目前输出的结果只是流水线的一级占比展示,perf stat还有一个参数 –td-level
其中
- Front End Bound(前端依赖)主要完成指令的译码,把获取的指令翻译为一系列的微指令,当cpu stalled在前端,说明cpu取值较慢或者取指或译指无法跟上后端处理的速度,或者可能存在icache-misses,无论是icache-misses 或者是 dcache-misses,可以通过尽可能将代码i 或者 变量数据d 局部化【更紧凑】来缓解。
- Back End Bound 主要是cpu处理前端发射过来的数据和指ca,其中core bound意味着指令的处理速度跟不上,memory bound意味着性能瓶颈分布在缓存上。如果cpu主要开销在后端,可以考虑使用neon/dsp来提高并行访问和计算。
- Bad Speculation: 主要指处理器的一些投机行为,如控制冒险(分支预测),数据冒险(预取)等,如果该指标占比较高,可能要考虑优化branch-misses;
- Retiring:指令被执行完,最终的retire动作,提交结果到寄存器或者内存,结构冒险可能会导致写回延迟
perf annotate
指令级分析函数热点瓶颈 常用用法:
1> perf record -ag ./demo 【生成perf.data文件】
2> perf annotate -k /path/to/vmlinux MaxPoolingRefine(symbols)
2> perf report 回车【进入交互页面,找到符号,输入a进入指令分析】
gperftools
原理:在进程启动后,开启一个指定频率的计时器,每次计时发送一个signal信号,从注册的Callback中携带的ucontext_t里边获取当前执行的上下文堆栈信息并存入map统计;
可以很直观的观察到,当前代码的性能都集中在哪条指令、对应的哪行源码上,左测为优化前的一个指令占比分布情况,可以看到循环内的add以及cmp比较指令占用了大部分的cpu指令周期;
该种情况下,流水线一定会在某个阶段,如backend的core bound和bad speculation阶段有一定程度的“堵塞”,解决方法就是充分发挥cpu多发射特性,减少流水线冒险及指令前后的依赖,来提高流水线的吞吐量,如loop unrolling,右图为循环展开后的指令cpu耗时分布,可以看到流水线阻塞情况有所好转。
全局统计
通过LD_PRELOAD指定libprofiler.so来使用
#指定采集的prof文件路径, 必须
export CPUPROFILE=/userdata/xxxx-cpu-profiler.prof
#指定开启和停止采样的信号量指令, 指定55是由于代码中注册了很多信号量处理函数,12无法生效
export CPUPROFILESIGNAL=55
#指定采样频率为每秒300次,默认每秒100次,可选
export CPUPROFILE_FREQUENCY=300
#指定预加载的so
export LD_PRELOAD="/userdata/libprofiler.so"
./demo
运行脚本后,可通过kill -55 pid开始采样,再次通过kill -55 pid结束采样
2.2 局部热点统计
2.3 结果转换
benchmark
性能测试框架,经常用来测试delay,验证优化效果。为了获取更稳定的结果,避免缓存等影响,在执行benchmark时,真正统计之前会预先跑几次循环达到预热waring up的效果,并且可以很灵活的测试在不同数据量以及多线程下的性能表现
Example
top-> down 方法
火焰图 ——> 找到函数级热点 -> perf annotate/perf stat -> 指令集流水线级热点
->Front-End Bound 取值 译码
-> Bad Speculation 分支预测
-> Core Bound 瓶颈
-> Memory Bound cache 缓存
热点分析 top -> down
火焰图平顶
代码review
例如 cache-miss 和 branch-miss情况
MaxPooling 潜在的3* 128 * 256 个处理的点
代码逻辑:
-
过滤每个点,临界值
-
获取kernel
具体代码实现:
-
一次遍历 h( w ( c: ) ) ),如果c0图中(i,j)为中心的点是以该点为中心的kernel范围内的最大值,则更新到最大值,然后一次遍历c1图中该点为中心的kernel最大值,并对比c0更新最大值,以此类推。
-
这种访存方式存在巨大的cache-misses,因为对每个点的处理,除了类间kernel提取需要上下跨越width-1与width+1之外,类间的提取要跳过128*256的范围去访问,这个会造成很大的cache-misses
-
经了解,该数组大于临界值的数量一般只有60个左右,占比60 / 9.8w, 而经过2,3步最终提取的最大值数量一般为20个左右,因此属于稀疏数组。
性能分析 优化
-
首先,以c( h ( w: )))形式,在循环中筛选出大于临界值的60个左右的点,这样可以更符合当前数据内容的格式,可以优化在1282563次循环中对数据的跳跃访问造成的cache-misses开销
-
在循环遍历9.8w个点中,再通过循环展开的形式,以及循环展开后,实行十混一的方式,合并if判断表达式,来减少cmp指令的执行次数,以此优化上图中分布较集中的add和cmp指令的阻塞瓶颈,优化后的指令热点分布以及耗时对比
优化结果验证
delay
流水线在投机阶段的占比也有所下降,perf stat统计的指令数,分支判断数,memory-bound都有所收益:
编写neon代码,对比循环展开的性能,循环展开层级性能对比,取最优方案
参考
https://zhuanlan.zhihu.com/p/447682231