引入
《性能之巅》作者 Brendan Gregg 发明的火焰图
示例代码
void loop() {
for (int i = 0; i < 10000000; i++) {
int j = i * i;
}
}
static const int ROWS = 2000; // 行数
static const int COLS = 4096; // 列数
static int arr[ROWS][COLS]; // 二维数组
void high_miss(void) {
int sum = 0;
for (int c = 0; c < COLS; c++) {
for (int r = 0; r < ROWS; r++) {
sum += arr[r][c]; // 高缺失率访问模式
}
}
}
void low_miss(void) {
int sum = 0;
for (int r = 0; r < ROWS; r++) {
for (int c = 0; c < COLS; c++) {
sum += arr[r][c]; // 低缺失率访问模式
}
}
}
int sleep_until_when(void) {
auto now = std::chrono::steady_clock::now();
auto timestamp = std::chrono::time_point_cast<std::chrono::milliseconds>(now)
.time_since_epoch()
.count();
auto remaining = 1000 - (timestamp % 1000); // 计算距离下一个整秒还有多少毫秒
return remaining;
}
void main(void) {
auto loop_warpper = [](std::function<void (void)> f) {
while (true) {
f(); // 循环调用传入的函数
}
};
std::thread([&](){
loop_warpper([](){
loop(); // 执行 loop 函数
high_miss(); // 执行高缺失率访问函数
low_miss(); // 执行低缺失率访问函数
std::this_thread::sleep_for(std::chrono::milliseconds(sleep_until_when())); // 等待距离下一个整秒的剩余时间
});
}).detach();
while (true) {
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}

perf 简单介绍
perf是一个强大的Linux性能分析工具,它可以用于收集和分析系统的性能数据。它提供了一系列的命令行工具,可以测量各种指标,如CPU使用率、内存使用情况、磁盘I/O、网络传输等。下面是perf工具的一些关键概念和组成部分:
- perf_events接口:perf工具利用perf_events接口来与Linux内核进行交互。这个接口允许perf工具注册事件,收集性能数据,并获取相关的硬件性能计数器数据。
- 事件:在perf工具中,事件是指一个需要测量和记录的特定硬件或软件活动。例如,可以设置事件来测量CPU周期、指令执行、缓存命中率等。
- 采样:perf工具通过采样机制来收集性能数据。采样是指在一定时间间隔内获取当前系统状态的过程。perf会在程序执行过程中定期采样CPU寄存器、内存地址和其他相关信息,从而获得系统的性能指标。
- 命令行工具:perf工具提供了一系列命令行工具,用于执行不同类型的性能分析任务。其中一些常用的工具包括perf stat(统计性能指标)、perf record(记录性能数据)、perf report(生成性能报告)等。
- 周期计数器:perf工具使用硬件的性能计数器来测量各种系统活动。这些计数器可以测量CPU周期、指令执行次数、缓存命中率等关键指标。perf工具通过perf_events接口访问这些计数器。
- 事件分析:perf工具可以对收集到的性能数据进行分析。它提供了多种分析功能,如调用图分析、热点函数分析、事件时间线分析等。这些分析功能可以帮助开发人员找到系统中的性能瓶颈,并进行优化。
perf的执行流可以简要概括为:配置事件、内核记录数据、触发event、执行采样、读取数据、数据分析
数据采样
perf基于内核event触发采样,在采样的过程大概分为两步,一是调用 perf_event_open 来打开一个 event 文件,而是调用 read、mmap等系统调用读取内核采样回来的数据。整体的工作流程图大概如下
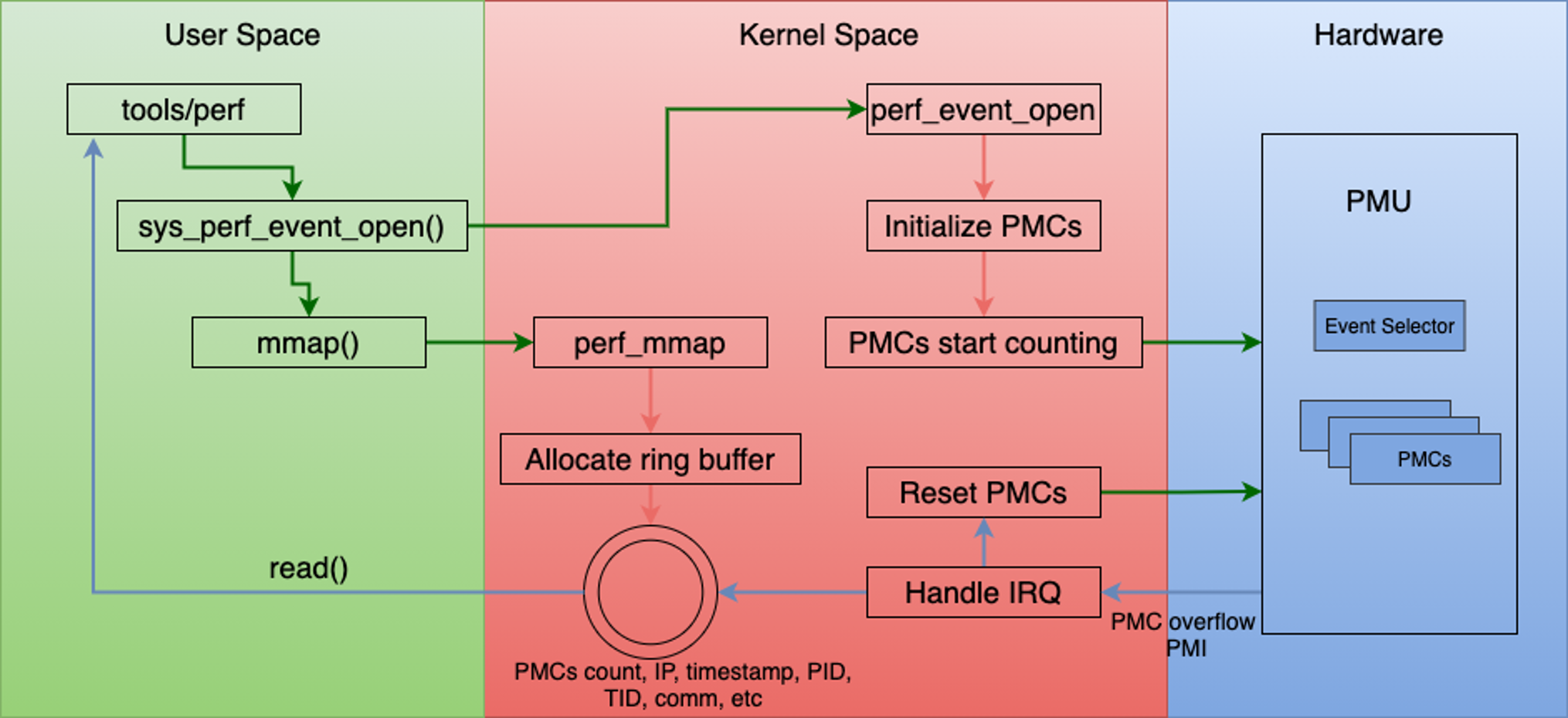
其中 perf_event_open 完成了非常重要的几项工作。
- 创建各种event内核对象
- 创建各种event文件句柄
- 指定采样处理回调
- 我们来看下它的几个关键执行过程。在 perf_event_open 调用的 perf_event_alloc 指定了采样处理回调函数,比如perf_event_output_backward、perf_event_output_forward等
static struct perf_event * perf_event_alloc(struct perf_event_attr *attr, ...) { ... if (overflow_handler) { event->overflow_handler = overflow_handler; event->overflow_handler_context = context; } else if (is_write_backward(event)){ event->overflow_handler = perf_event_output_backward; event->overflow_handler_context = NULL; } else { event->overflow_handler = perf_event_output_forward; event->overflow_handler_context = NULL; } ... }
当 perf_event_open 创建事件对象,并打开后,硬件上发生的事件就可以出发执行了。内核注册相应的硬件中断处理函数是 perf_event_nmi_handler
//file:arch/x86/events/core.c
register_nmi_handler(NMI_LOCAL, perf_event_nmi_handler, 0, "PMI");
该终端处理函数的函数调用链经过 x86_pmu_handle_irq 到达 perf_event_overflow。其中 perf_event_overflow 是一个关键的采样函数。无论是硬件事件采样,还是软件事件采样都会调用到它。它会调用 perf_event_open 时注册的 overflow_handler。我们假设 overflow_handler 为 perf_event_output_forward
void
perf_event_output_forward(struct perf_event *event, ...)
{
__perf_event_output(event, data, regs, perf_output_begin_forward);
}
在 __perf_event_output 中真正进行了采样处理
//file:kernel/events/core.c
static __always_inline int
__perf_event_output(struct perf_event *event, ...)
{
...
// 进行采样
perf_prepare_sample(&header, data, event, regs);
// 保存到环形缓存区中
perf_output_sample(&handle, &header, data, event);
}
如果开启了 PERF_SAMPLE_CALLCHAIN,则不仅仅会把当前在执行的函数名采集下来,还会把整个调用链都记录起来。
//file:kernel/events/core.c
void perf_prepare_sample(...)
{
//1.采集IP寄存器,当前正在执行的函数
if (sample_type & PERF_SAMPLE_IP)
data->ip = perf_instruction_pointer(regs);
//2.采集当前的调用链
if (sample_type & PERF_SAMPLE_CALLCHAIN) {
int size = 1;
if (!(sample_type & __PERF_SAMPLE_CALLCHAIN_EARLY))
data->callchain = perf_callchain(event, regs);
size += data->callchain->nr;
header->size += size * sizeof(u64);
}
...
}
这样硬件和内核一起协助配合就完成了函数调用栈的采样。后面 perf 工具就可以读取这些数据并进行下一次的处理了
数据分析
使用perf的输出来生成火焰图,常规生成步骤包括perf record、perf script、stackcollapse-perf.pl、flamegraph.pl
perf record
启动性能数据的采集,并将数据保存到一个文件中,通常是二进制文件格式(如perf.data),其内容包括:
- 文件头(Header):包含 perf 版本、命令行参数等元数据信息。
- 样本数据(Sample Data):记录了在采样过程中收集到的性能数据,包括时间戳、事件、CPU ID、调用栈等信息。每个样本都对应一个特定的事件,例如指令执行、函数调用等。
- 符号表(Symbol Table):包含二进制可执行文件的符号信息,用于解析调用栈中的函数和地址。
- 事件描述符(Event Descriptors):描述了每个事件的配置和属性。
perf script
此步骤使用perf工具解析perf.data文件中的样本数据,并将其转换为可读的格式,生成的文件内容包括:
- 解析后的样本数据(Decoded Sample Data):将原始的二进制样本数据解析为人类可读的格式,显示了每个样本的具体信息,如时间戳、事件名称、CPU ID、调用栈符号等
- 函数注解(Function Annotations):在解析的样本数据中,perf script 还可以显示函数注解,即对函数调用的描述和注释
- 其他信息:perf script 还可以提供其他有关样本数据的附加信息,如进程、线程、共享库信息等
以示例代码的perf script输出为例,第一行各列的含义为:
- test:线程名
- 15656:tid
- 233693.200442:采样时间(从系统启动开始计算,单位s)
- 1:采样间隔(事件计数器溢出值),详见下文【perf采样间隔】
- cycles:事件名
stackcollapse-perf.pl
用于折叠和转换perf样本数据的脚本工具,内部执行步骤
- 将perf script输出的样本数据进行折叠,将相同函数调用路径的样本数据合并为一个条目
- 生成的文件内容是折叠后的样本数据,每行包含:线程名、调用路径、样本数
flamegraph.pl
火焰图绘制工具
- 接收折叠后的样本数据作为输入,并根据函数调用路径和样本计数生成火焰图的SVG文件
- 生成的文件内容是一个可交互的火焰图,显示了函数调用路径和样本计数的层次结构表示
额外指令
perf report
不依赖火焰图,直接查看统计结果,方便临时调试
额外值得关注
perf采样间隔
Perf基于事件采集,以PMU中的cycles事件为例,每个cpu时钟PMU计数器均会+1,
很明显不可能每次+1时都触发采样。因此,perf record支持-c和-F两种采样间隔配置方式:
- -c选项(或–counter):
- -c选项基于事件计数器,可以指定采集事件的计数器溢出值,它以事件发生的次数为依据来决定采样间隔
- 如,perf record -c 1000表示每发生1000次事件时进行一次采样
- -F选项(或–freq):
- -F选项基于时间间隔,可以指定采集数据的时间间隔,即采样的频率
- 该选项指定了每秒钟进行多少次采样。例如,perf record -F 100表示每秒进行100次采样。
选择使用-c还是-F取决于关注的是事件的数量还是时间间隔
由于perf本质上基于事件触发,并没有在内部维护一个定时器来触发采样,因此,使用-F指定采样间隔时,实际上是由kernel根据事件数量,动态调整计数器溢出值,相当于动态使用-c参数配置事件计数器值